Try SDXL Turbo For Free!
Enter your prompt and wait for a second, let SDXL Turbo amaze you.

Create an ultra-realistic digital image of a traditional Japanese tea ceremony. The scene is set in a serene, tatami-matted room with sliding shoji doors that open to a view of a peaceful Japanese garden. The setting includes traditional elements like a chawan (tea bowl), a bamboo tea whisk (chasen), a small lacquered tea caddy (natsume), and a cast-iron kettle (tetsubin) resting on a sunken hearth (ro). A tokonoma (alcove) in the background displays a hanging scroll with calligraphy and an ikebana flower arrangement. The soft, natural lighting highlights the calm and meticulous atmosphere of the ceremony, capturing the essence of this iconic aspect of Japanese culture.

Foto studio keluarga 6 orang, wearing batik clothes of the same blue color, father age 50 years, thin, black hair, long face, not bald, mother age 35 years, wearing jilbab, child 1 female age 10 years, child 2 male age 6 years, child 3 female age 4 years, child 4 female age 2 years, background living room, realistic photo

a girl with dark spiky bob sitting alone in the theatre, she is wearing white blouse with short sleeves, black shorts and long white golf socks

Long red hair girl in garden in white dress

fantasy football spongebob bikini bottom

An Indian king riding in river, having fish in one hand and wife in other hand

Many blue prickly aliens with glowing bodies playing on potatoe playground on alien planet

Sengichijou kyou

(Best Quality, Masterpiece), middle, (fantasy theme), Indonesian football magazine front cover, concept art, design, magazine design, Full body realistic 4D caricature with a big head. a 25 year old man, Iko Uwais plays for the Indonesian national judo team. wearing a dark blue judo uniform and a belt that says 'RANGGA'. standing with right hand clenched in front and legs open, alert position, (epic composition, epic proportions), bright colors, text, diagrams, advertisements, magazine titles, typography,

rainy evening in the small, picturesque town

A cat chasing a mouse.

Little boy aged 9 wearing a my little pony dress

Middle ground. A asian woman with transparent skin and a skeleton inside, facing the camera and looking over her shoulder. Bioluminescence, bizarre patterns of different colors on the skin. The image is illuminated with warm orange light against a black background. hasselblad h6d-400c professional photography.

A colossal dragon soars majestically above stormy seas, its massive wings cutting through dark clouds. The dragon's scales shimmer with deep shades of red and gold, reflecting the ominous lightning that cracks the sky. The ocean below is tumultuous, with towering waves crashing violently against jagged rocks. The scene is bathed in a dramatic, moody atmosphere, with dark, rich tones and intricate details that capture the epic and ancient feel of the 'House of the Dragon' series.

Ratan tata, digital art caricature in the style of pop surrealism, vector illustration, high resolution, high quality, high detail, hyper realistic, hyper detailed, ultra realism, high dynamic range, high contrast, high color film grain.

a fantasy castle with lake in front of entrance and cloudy sky

a hermit with a long beard kneels and prays

pregnant female dragon, which spits fire

Three sisters wearing traditional Chinese attire are standing together, taking a selfie in front of a large mirror. Behind the mirror, there are portraits of their ancestors, along with offerings for the Ghost Festival, including incense, fruits, and various traditional foods. An incense burner with lit incense sticks is also placed on the altar. The scene captures the cultural essence of the Chinese Ghost Festival, with the sisters smiling warmly, surrounded by the atmosphere of reverence and tradition.

Create an ultra-realistic digital image of two sumo wrestlers facing each other in a traditional Japanese setting. The wrestlers, both large and muscular, are dressed in traditional mawashi (sumo belts) and are locked in intense eye contact, ready for a bout. The setting features a sumo ring (dohyo) with a clay surface and a straw bales boundary. Around the ring, the scene is adorned with Japanese cultural elements, such as banners with kanji characters, hanging paper lanterns, and a torii gate in the background. The atmosphere is enhanced by the presence of a gyoji (referee) in traditional attire, standing to the side. The lighting captures every detail of the wrestlers' physiques, the texture of the clay, and the intricate designs on the surrounding elements, making the scene feel vibrant and true to the iconic Japanese sport.

cyber soldier with gear armor, handsome hunk, nice hair, happy face. nice boots. realistic photo.

realistic architecture photography, cinematic. A concept for a sustainable school in harmony with the landscape, located in Zermatt, Switzerland. Realistic Intoir Views

number of guys posing together wearing gen z kind of retro clothes for a fashion website and it should be a full sie images and all the guys should have beard, some with no beard, all of them smiling and it should be kind of a candid photo looking towards THE CAMERA

A Fivem Logo that takes the shape of the letter P and has the color blue. It should include a wave in the P that especially at the end contains those typical wave particle elements. The background should be black with blue light particles.

Create a pub sign for the 'Rother Hof'

Pixel style, a little girl with double ponytails, wearing red clothes, holding a camera

car service engine cooling system cleaning

I need to generate an image of a cartoon engineer, this engineer needs to wear a yellow hard hat and have a beard. Age around 40 to 50.

I want a design for a Chilean hamburger brand that is realistic, friendly, and includes elements such as the Southern Cross and the colors of the Magallanes flag, with the Torres del Paine in the background.

A white wall with a large glass window, outside a port with several boats, yachts, all well lit and with the moon in the background.

17 year old girl wearing Goku costume from Dragonball, muscular

A burly cook and a gaunt middle-aged man in a medieval castle came out to greet a handsome tall man with shoulder-length russet hair, wearing a black medieval camisole and brown boots, and a young chubby blonde, with fluffy long braids and a simple peasant dress. Against the background of a medieval farmstead in a castle.

clean, sharp, vectorized mon, company logo, icon, trending, modern and minimalist, of a fox head, curved. Clean modern fox logo. Simple minimal animal vector icon. 'Grant' underneath the fox head

Create a dark, eerie forest scene at night with a gloomy, foggy atmosphere. In the background, depict a group of witches, dressed in tattered black robes and wearing wide-brimmed pointed hats. They should be holding dimly lit candles, forming a semi-circle. The background witches should be shadowy and indistinct, adding to the mysterious and ominous mood. In the center foreground, place a large, terrifying witch who stands out as the focal point. She should be facing forward, with a pale, ghostly face, dark makeup around her piercing eyes, and long, disheveled greenish-black hair. Her expression should be menacing, with a chilling, terrifying look. The lighting should emphasize her face, making it glow against the dark, muted background, creating a sense of unease and fear.

Cover for Mindfulness Diary

Pixel style, a little girl with double pigtails, wearing a red New Year's dress
What is Stable Diffusion 3 and what's new in it ?
Innovative Technologies and Architecture
Released on April 17, 2024, Stable Diffusion 3 features cutting-edge technologies such as the rectified flow technique and the Multimodal Diffusion Transformer architecture. These advancements streamline the image generation process and improve the integration of visual and textual data, significantly enhancing the quality and accuracy of the generated images.
Enhanced Text and Image Quality
The model utilizes a powerful combination of text encoders, including CLIP G14, CLIP L14, and T5 XXL, which greatly improve the text rendering capabilities, particularly in terms of spelling accuracy. It is trained on diverse datasets like COCO 2014 and ImageNet, using advanced de-duplication techniques to ensure a wide variety of high-quality training examples.
Scalability and Open-Source Ethos
Demonstrating its scalability, Stable Diffusion 3 shows continuous improvement with increases in model size and data volume. Stability AI’s commitment to open-sourcing the model promotes transparency in AI development and helps reduce environmental impacts by avoiding redundant computational experiments. This approach ensures that the benefits of AI advancements are accessible to a broader community.
SDXL Turbo Examples

Key Features and Benefits of SDXL Turbo
Revolutionary Performance
SDXL Turbo sets a new standard in text-to-image generation with its groundbreaking Adversarial Diffusion Distillation (ADD) technology. This innovative approach allows for rapid, single-step image generation, a significant leap forward from the traditional multi-step processes.
Enhanced Image Quality
Unlike other models, SDXL Turbo produces images of exceptional clarity and detail. By leveraging the strengths of Generative Adversarial Networks (GANs), it ensures images are crisp and vivid, avoiding common issues like blurriness or artifacts.
Real-Time Generation Capabilities
Ideal for applications demanding speed and efficiency, SDXL Turbo excels in generating high-quality images in real-time. This makes it a perfect fit for dynamic environments such as video games, virtual reality, and instant content creation.
Computational Efficiency
On high-end GPUs like the A100, SDXL Turbo can generate a 512x512 image in just 207ms, including prompt encoding, a single denoising step, and decoding. This efficiency represents a monumental improvement in both time and energy consumption over previous models.
Wide Range of Applications
The model’s versatility makes it suitable for diverse applications, from creating artistic and design works to aiding in educational and research projects. Its real-time generation ability opens new possibilities in interactive media and online content creation.
User Accessibility
SDXL Turbo’s ease of use is a key feature. With simple setup requirements and an intuitive interface on platforms like Clipdrop, it’s accessible to both professionals and hobbyists alike, regardless of their technical background. - Research and Development Opportunities: For researchers and developers, SDXL Turbo presents an unparalleled opportunity to explore advanced AI in image synthesis. The model’s unique approach and performance offer a rich ground for academic and commercial research.
In-Depth Technical Details and Model Information of SDXL Turbo
Innovative Model Architecture
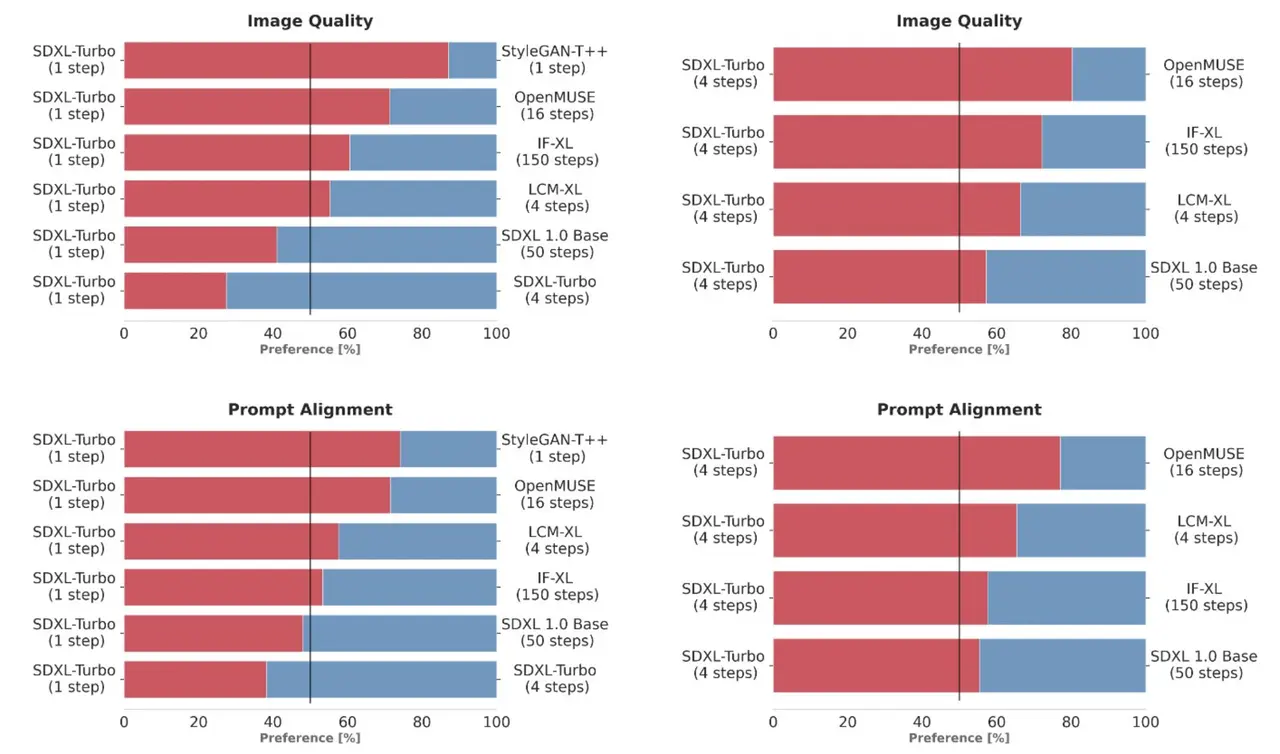
At the core of SDXL Turbo lies the novel Adversarial Diffusion Distillation (ADD) technique. This unique architecture combines the best of generative adversarial networks (GANs) with diffusion model technologies, enabling the model to synthesize high-fidelity images in just a single step. This significant technical innovation represents a leap forward from the foundational SDXL 1.0 model, making SDXL Turbo more efficient and powerful in image generation.
Comprehensive Research and Development
Developed and funded by Stability AI, SDXL Turbo is the result of extensive research and development efforts. It stands as a distilled version of the SDXL 1.0, specifically trained for real-time synthesis. The model's design and training process are detailed in an extensive research paper, which is available for public access. This document offers deep insights into the technical workings and the innovative aspects of SDXL Turbo.
Technical Specifications
SDXL Turbo excels in generating photorealistic images from text prompts in a single network evaluation. This capability is a result of the Adversarial Diffusion Distillation method, which allows for high-quality sampling in one to four steps. The model is fine-tuned from the base of SDXL 1.0, maintaining high image quality while dramatically reducing the steps required for image synthesis.
Model Accessibility and Resources
For researchers and AI enthusiasts, SDXL Turbo’s model weights and code are readily available on platforms like Hugging Face. Additionally, the model’s implementation can be found in Stability AI's generative-models GitHub repository, which includes popular diffusion frameworks for both training and inference. These resources are instrumental for anyone looking to explore or utilize this state-of-the-art model in their projects or research.
Interactive Demonstrations and Tutorials
To facilitate understanding and adoption of SDXL Turbo, the website can feature interactive demos and tutorials. These resources can help users experience the model's capabilities firsthand and guide them through its various applications, from simple text-to-image generation to more complex image-to-image transformations.
Links to Further Reading and Research Papers
Providing direct links to the research paper and other technical documents allows visitors to delve deeper into the science and engineering behind SDXL Turbo. These resources are crucial for academics, researchers, and technology enthusiasts who wish to gain a comprehensive understanding of the model's inner workings.
Download, Trial, and Usage Information of SDXL Turbo
Free Trial and Experience on sdxlturbo.ai
The most exciting feature for visitors to sdxlturbo.ai is the opportunity to experience and use SDXL Turbo for free. Emphasize this at the forefront of the section: "Try SDXL Turbo firsthand at no cost on sdxlturbo.ai! Experience the power of real-time text-to-image generation directly through our platform." This invitation allows users to engage with the technology immediately, showcasing the model's capabilities and user-friendliness.
Easy Accessibility for All Users
Highlight the ease with which both novices and experts can access and use SDXL Turbo on the website. The platform is designed to be intuitive, ensuring that even users with minimal technical background can start generating images in moments. This feature broadens the appeal of SDXL Turbo, making it accessible to a wide audience, including educators, artists, researchers, and hobbyists.
Model Download and Implementation
For those interested in more technical engagement, provide clear instructions and links for downloading SDXL Turbo’s model weights and code from repositories like Hugging Face. This section caters to developers and researchers looking to integrate SDXL Turbo into their own projects or conduct in-depth analysis and customization.
SDXL Turbo Related Tweets
Frequently Asked Questions
What is SDXL Turbo?
SDXL Turbo is a state-of-the-art text-to-image generation model that utilizes Adversarial Diffusion Distillation (ADD) for high-quality, real-time image synthesis.
Is SDXL Turbo free to use?
Yes, SDXL Turbo is available for free, non-commercial use on sdxlturbo.ai, where users can experience and test its capabilities.
Can I use SDXL Turbo for commercial purposes?
Currently, SDXL Turbo is released under a non-commercial research license. For commercial use, please contact us through sdxlturbo.ai for further information.
How does SDXL Turbo differ from other text-to-image models?
SDXL Turbo leverages ADD technology, enabling it to generate high-quality images in a single step, significantly faster than traditional multi-step models.
What are the system requirements to use SDXL Turbo?
SDXL Turbo can be used on most modern systems with internet access. For developers, using a system with a capable GPU like NVIDIA's A100 enhances its performance.
Can I integrate SDXL Turbo into my own applications?
Yes, developers can integrate SDXL Turbo into their applications using the model weights and code available on Hugging Face and GitHub, adhering to the non-commercial license terms.
What image resolution does SDXL Turbo support?
SDXL Turbo is optimized for generating 512x512 pixel images, balancing quality and computational efficiency.
Does SDXL Turbo support text-to-video generation?
Currently, SDXL Turbo specializes in text-to-image generation. Text-to-video capabilities are not available in this version.
How can I access SDXL Turbo’s model weights and code?
The model weights and code are available on Hugging Face and Stability AI’s generative-models GitHub repository.
Are there any limitations to the content SDXL Turbo can generate?
Yes, SDXL Turbo may have limitations in rendering legible text, faces, and certain complex scenarios. It’s also governed by an ethical use policy to prevent misuse.
Can SDXL Turbo generate images from any text prompt?
SDXL Turbo is designed to generate images from a wide range of text prompts, though its accuracy and quality may vary depending on the prompt’s specificity and complexity.
Is it possible to customize images generated by SDXL Turbo?
Yes, users can influence the outcome by adjusting the text prompts, though the current version does not support fine-grained control over every aspect of the generated image.
How does SDXL Turbo ensure the ethical use of AI?
SDXL Turbo adheres to Stability AI’s Acceptable Use Policy, which guides against generating harmful or misleading content.
What support is available for new users of SDXL Turbo?
New users can access a range of resources, including tutorials, user guides, and a community forum on sdxlturbo.ai.
Can I contribute to the development of SDXL Turbo??
Yes, developers and researchers are welcome to contribute, especially those focusing on AI and image generation technology, by adhering to the guidelines provided on our repository.
Are there any plans to improve SDXL Turbo further?
Continuous improvements and updates are planned, with a focus on enhancing performance, expanding capabilities, and ensuring ethical AI practices.
Can SDXL Turbo be used for educational purposes?
Absolutely, SDXL Turbo is a valuable tool for educational purposes, particularly in fields related to AI, computer graphics, and media studies.
How does SDXL Turbo handle data privacy and security?
User data privacy and security are top priorities. SDXL Turbo complies with all relevant data protection regulations and does not store personal data without consent.
Is there a community for SDXL Turbo users?
Yes, there’s an active online community where users can share experiences, get help, and discuss best practices.
Where can I find more detailed documentation on SDXL Turbo?
Detailed documentation is available on sdxlturbo.ai and within the repositories on Hugging Face and GitHub.